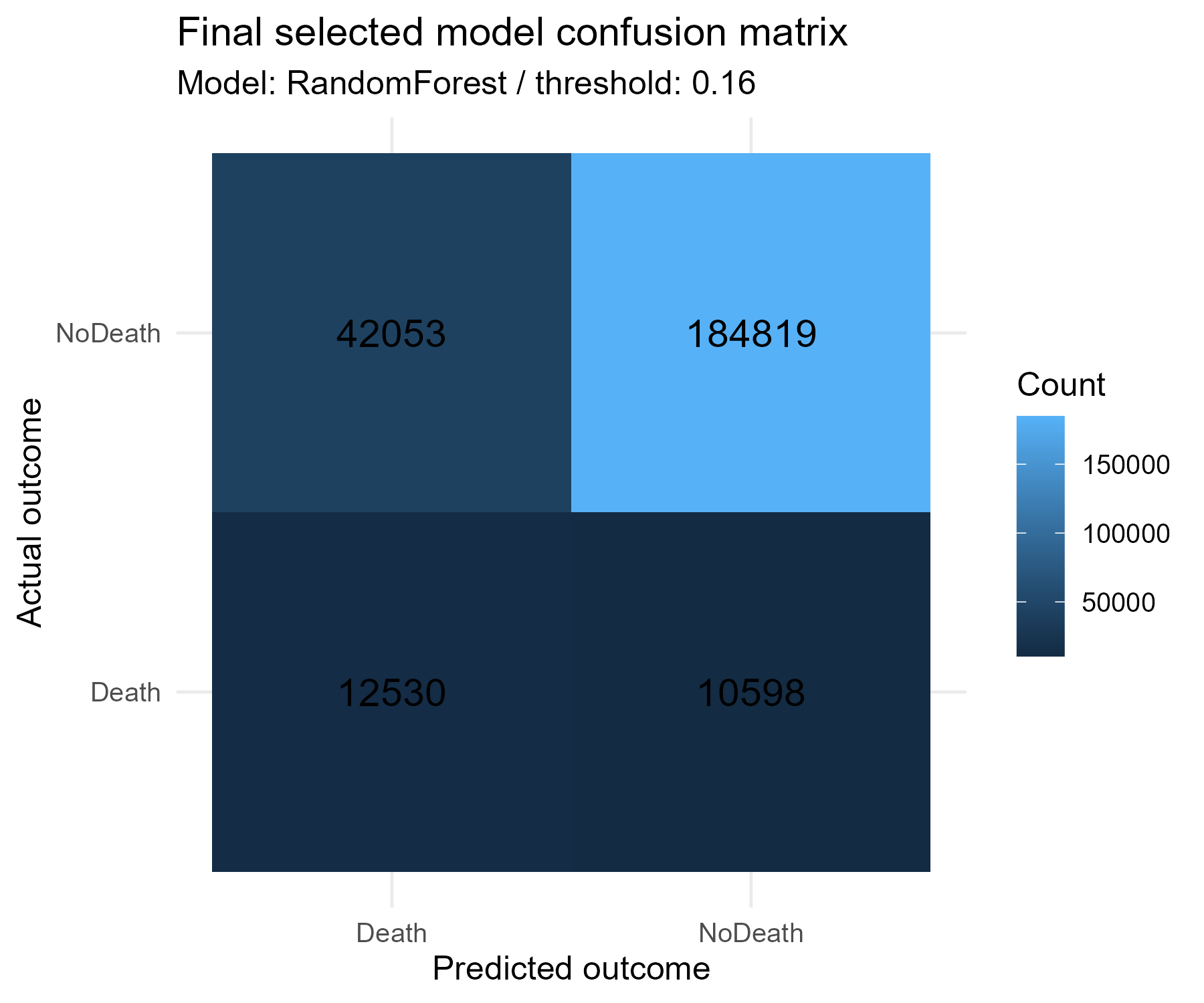
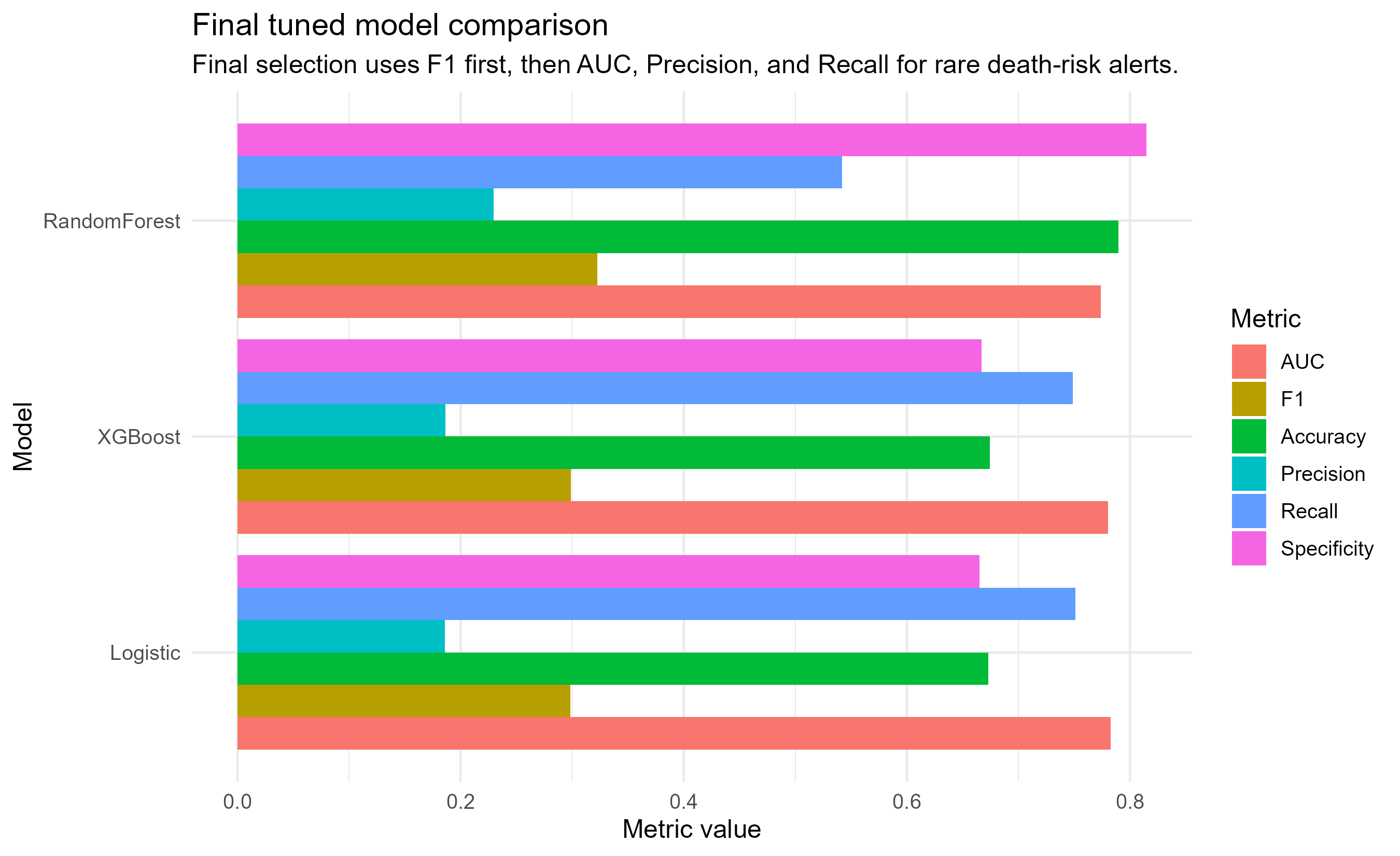
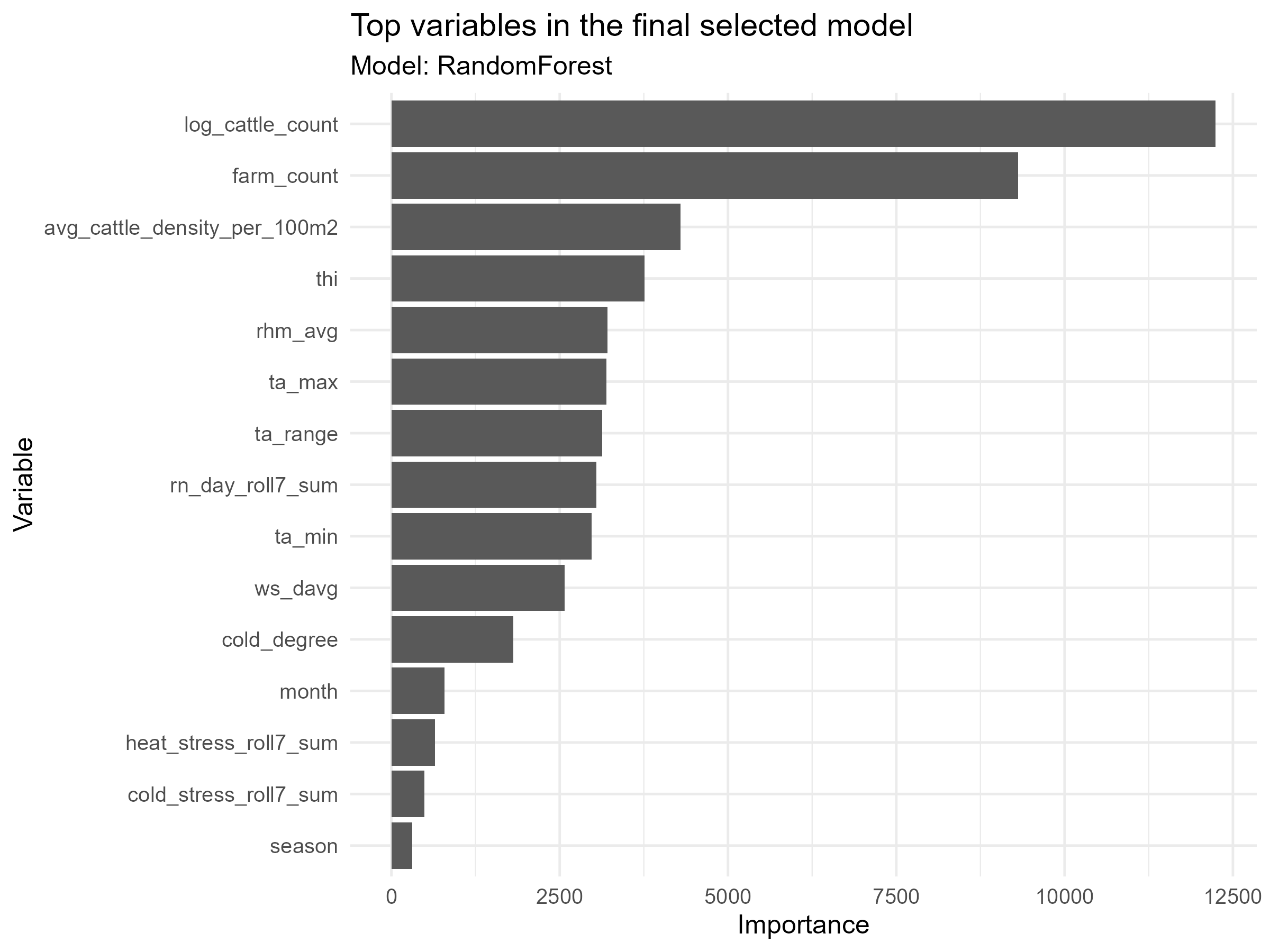
Exploratory Data Analysis
데이터가 말해준 것
"폭염이 위험하다"는 초기 가설과 달리, EDA 결과 저온·일교차가 더 위험하다는 반직관적 발견이 모델링 방향을 결정했습니다.
저온이 더 위험하다
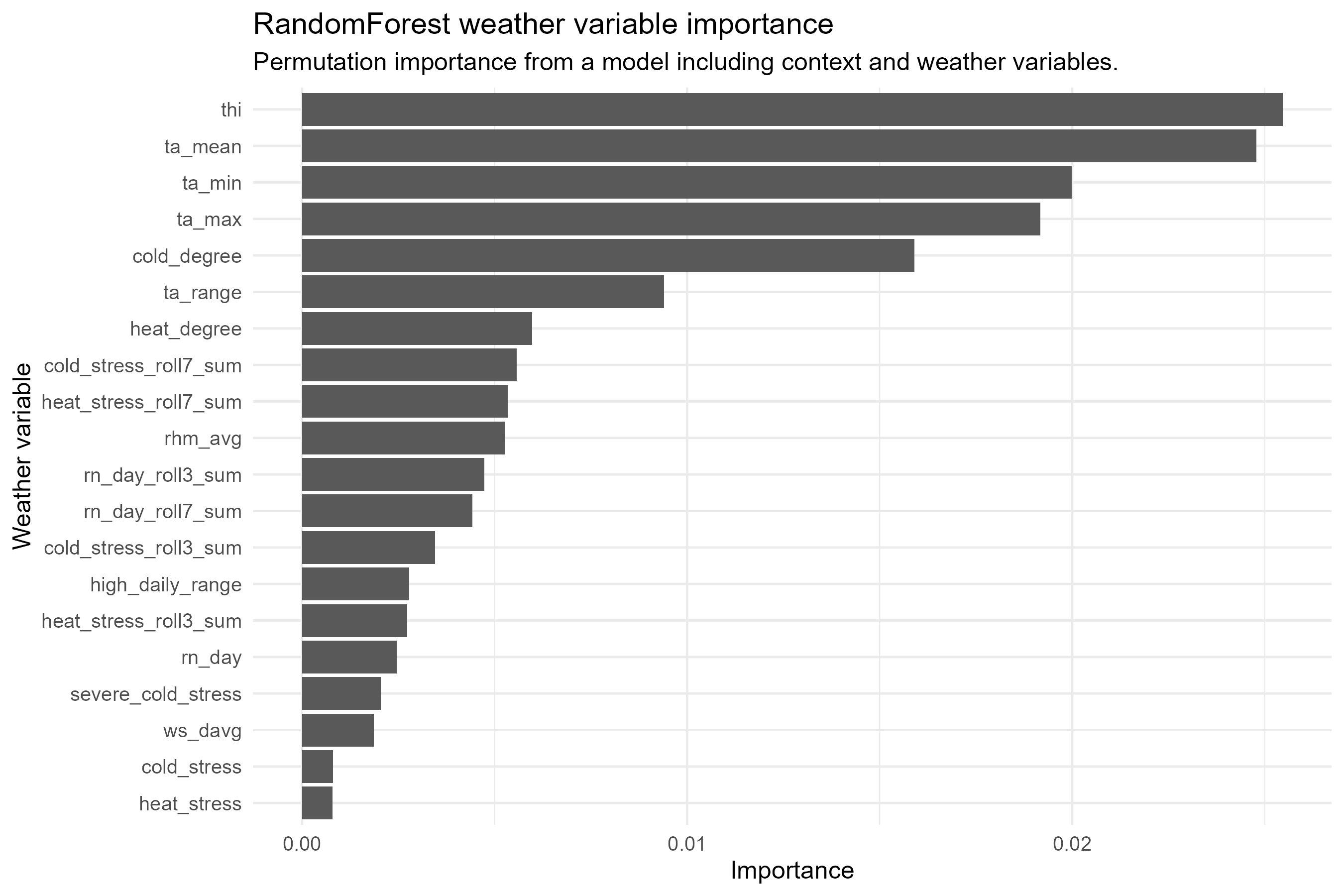
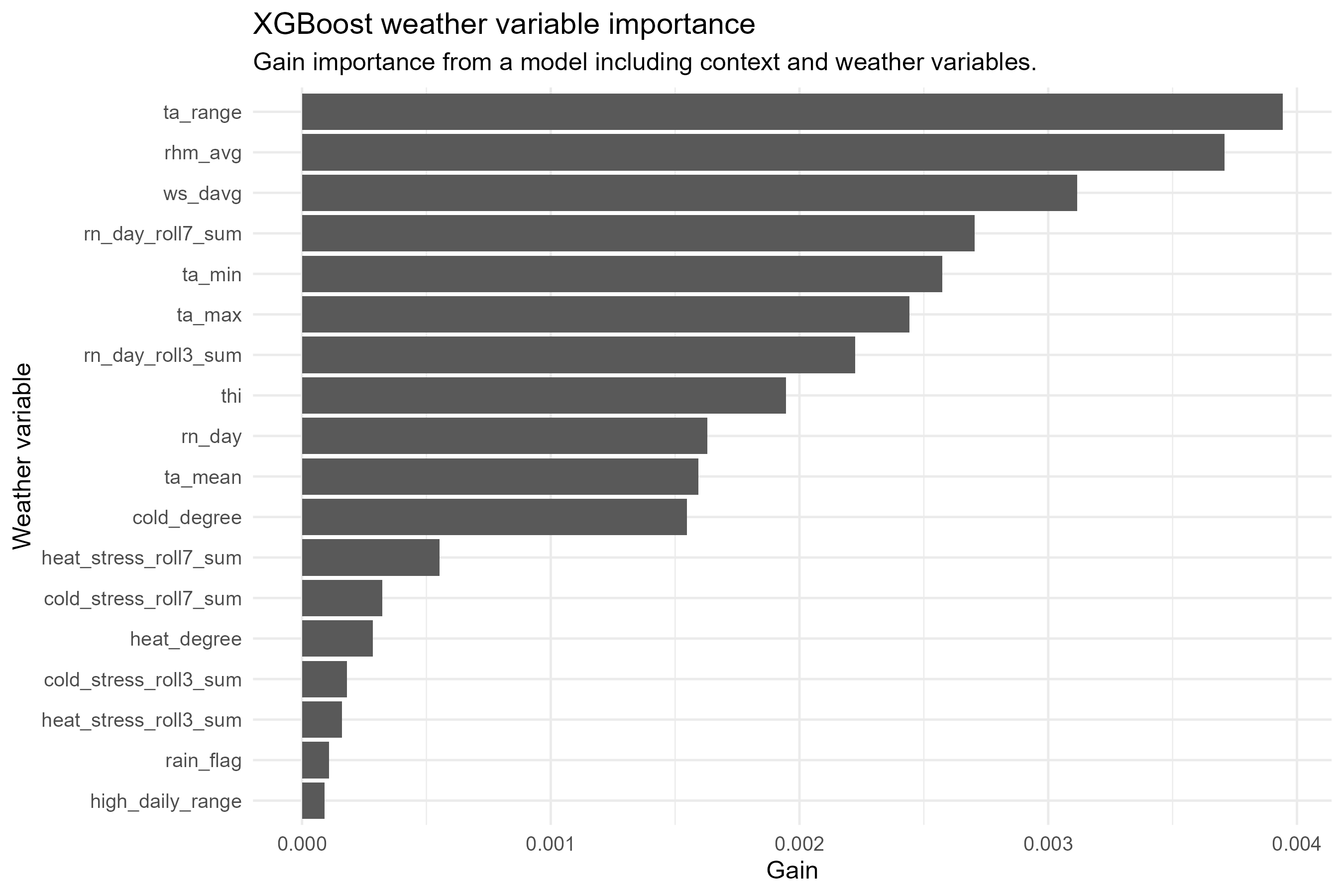
고온보다 저온·한랭 스트레스 변수가 폐사율과 더 높은 상관. THI < 45 구간 폐사율 0.0888로 최고 → 폭염 중심 가설을 기각
겨울 > 봄 > 여름 > 가을
계절별 평균 폐사율: 겨울(0.086) > 봄(0.084) > 여름(0.074) > 가을(0.071). 저온 환경에서의 설사 발생이 핵심 원인
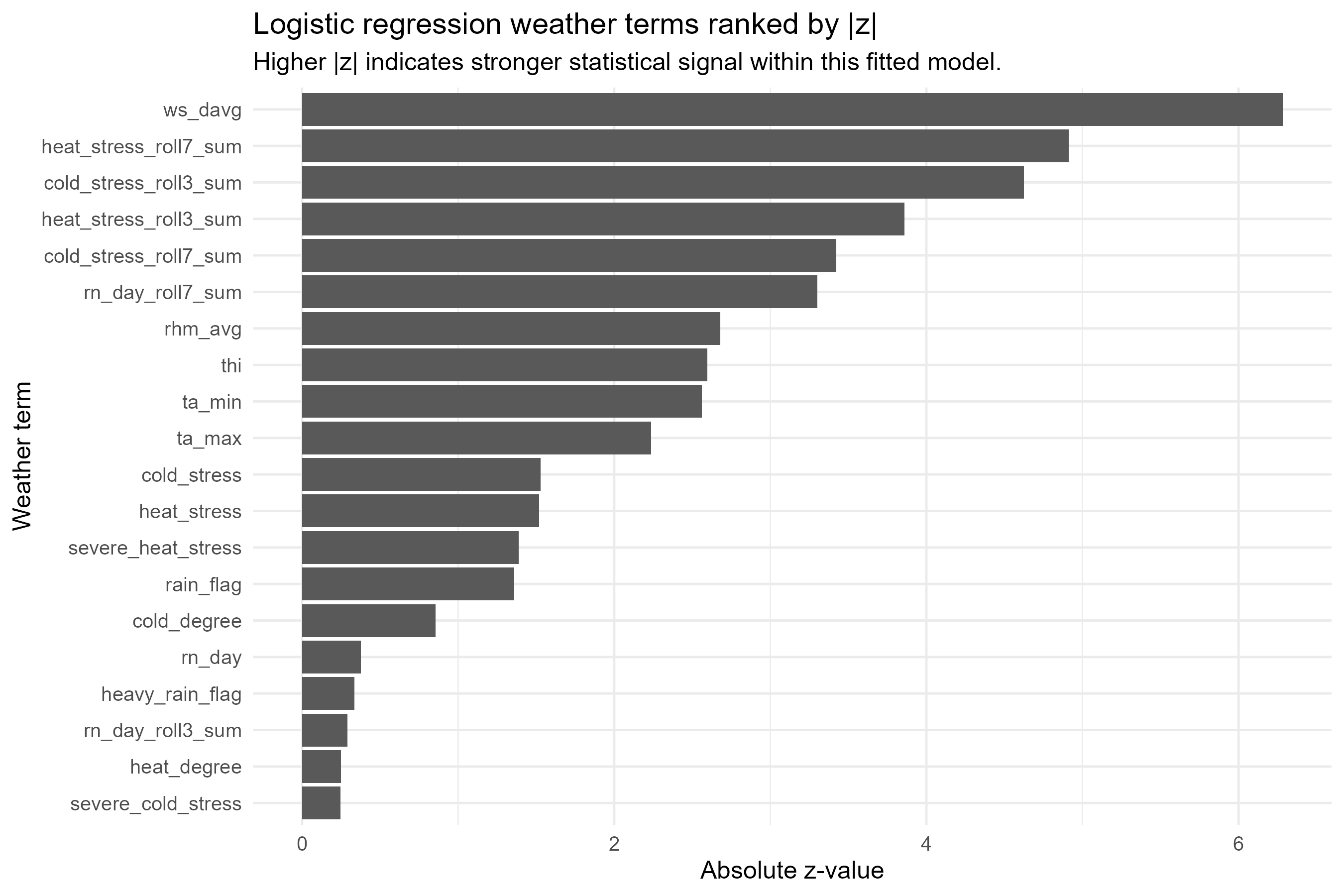
일교차 = 1순위 변수
Spearman 상관계수 1위(0.029). 15℃ 이상 구간에서 폐사율 최고. 체온 조절 능력이 약한 송아지에게 급격한 온도 변화가 치명적
사고 과정
처음에는 "여름 폭염 = 위험"이라고 팀 전체가 가정했습니다. 하지만 상관분석과 구간별 폐사율 분석을 해보니 cold_stress, ta_range(일교차), ta_min(최저기온)이 상위를 차지했습니다. 논문을 다시 찾아보니 국립축산과학원 10년 데이터에서도 동일한 패턴이 확인되어, 모델링 방향을 저온/일교차 중심으로 전환했습니다.
분석 시각화
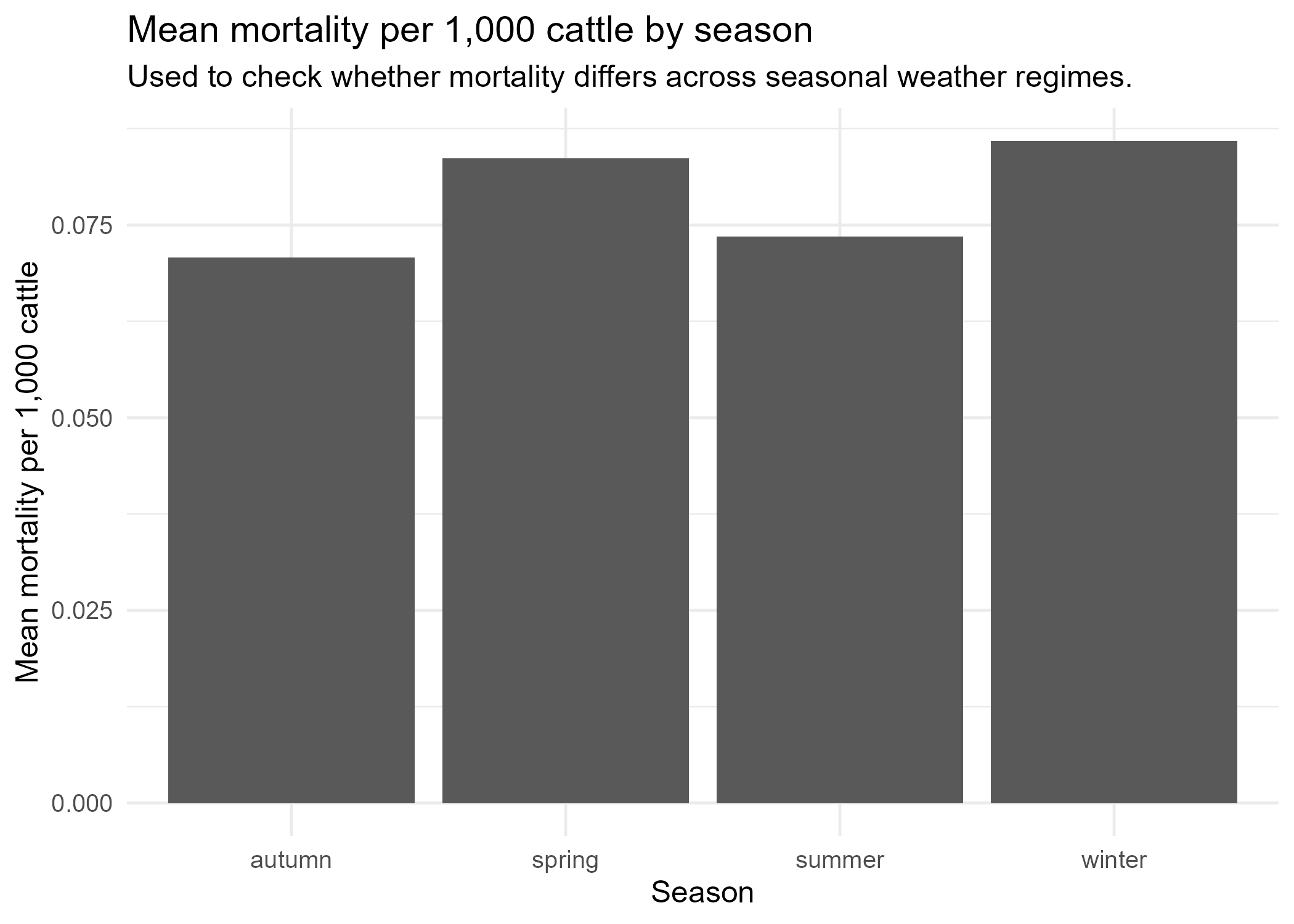
계절별 1,000마리당 평균 폐사 두수
기상 변수-폐사율 Spearman 상관계수 순위
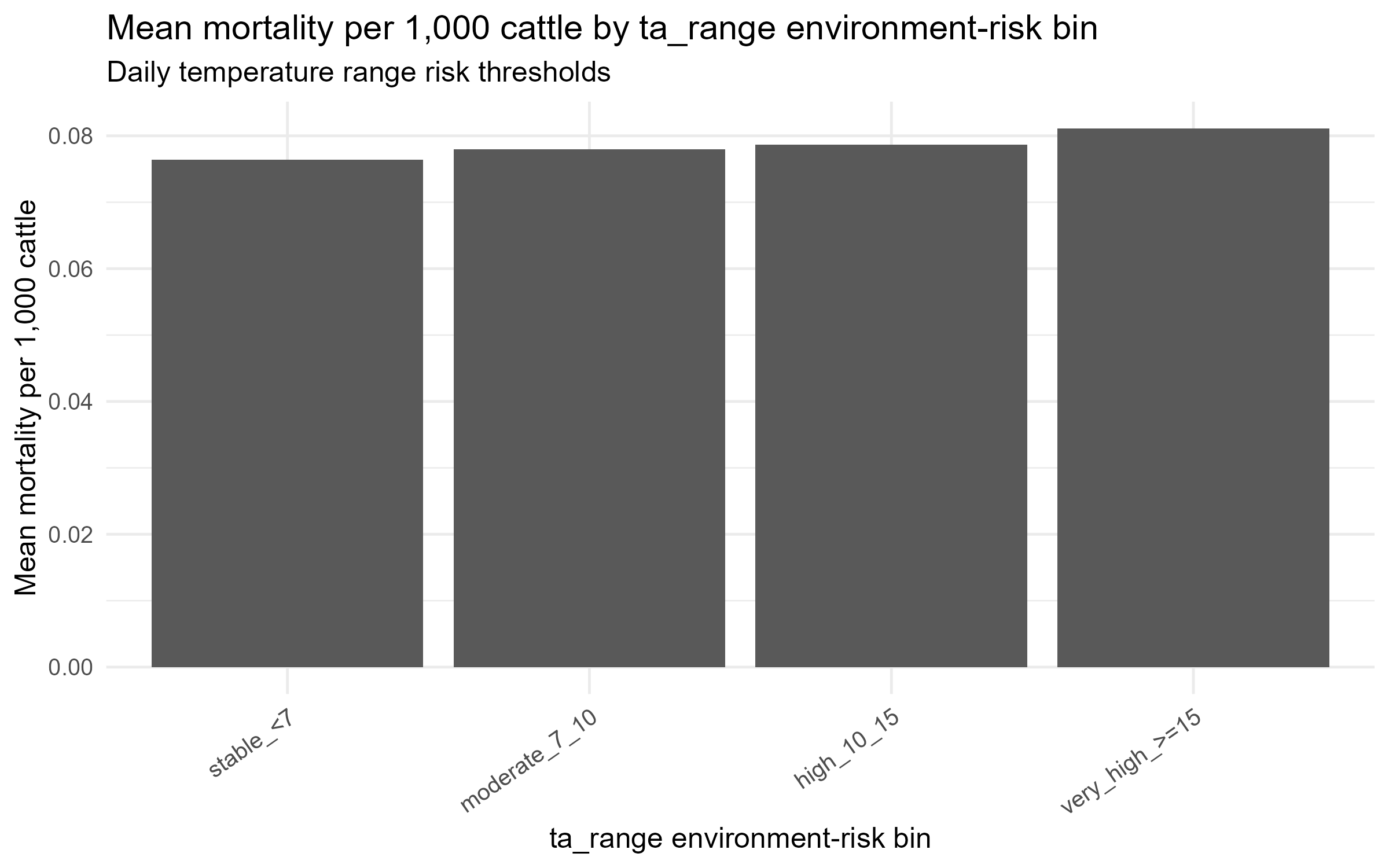
일교차 구간별 평균 폐사율
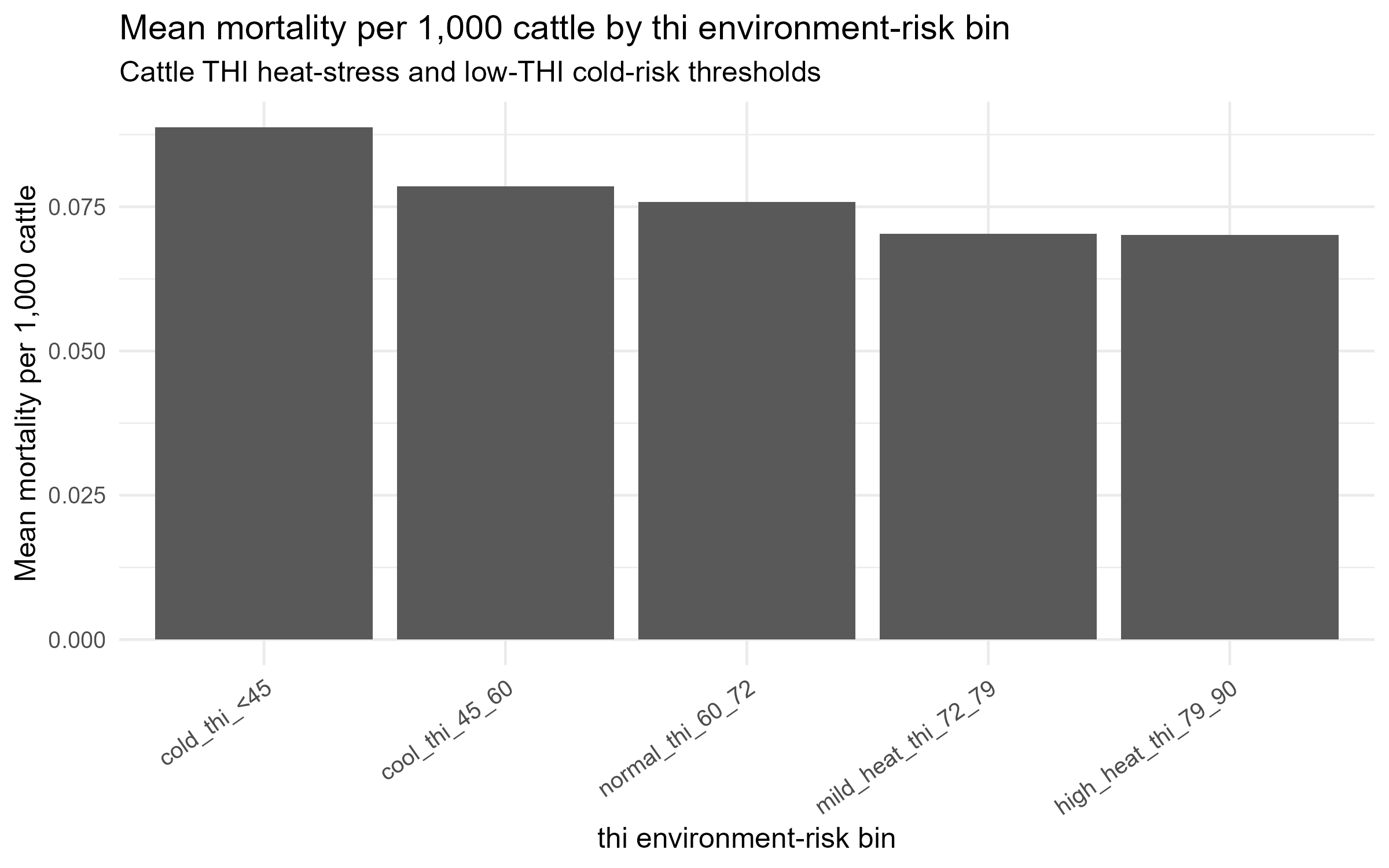
THI 구간별 평균 폐사율 — 저온 구간이 최고
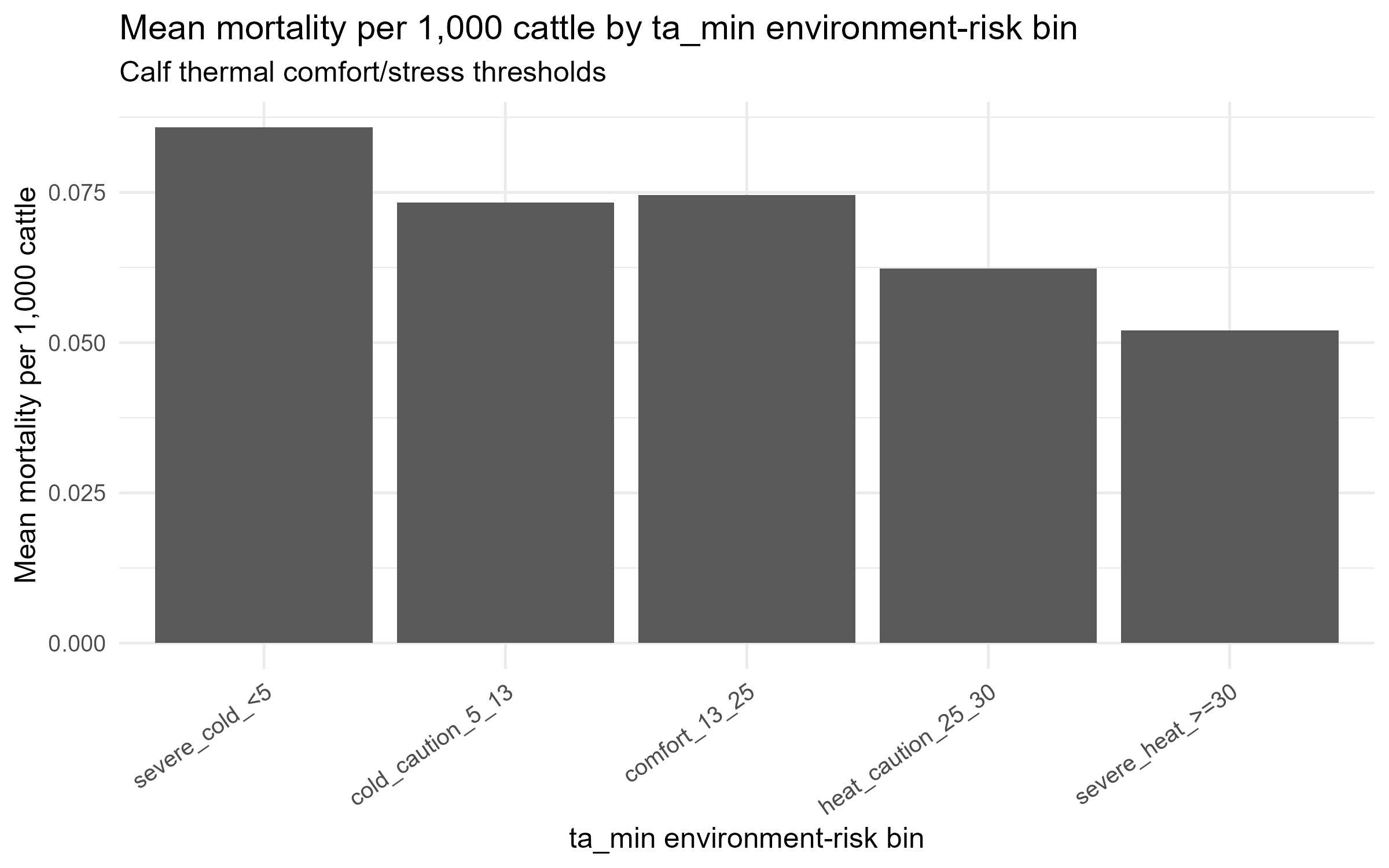
최저기온 구간별 평균 폐사율
평균 습도 구간별 평균 폐사율